Synthetic eye tracking: teaching NLP models how people read
TL;DR
- While reading, people linger on some words and skip or revisit others. That trace (a scanpath) carries a usable signal about what matters in the text.
- Collecting it needs eye-tracking hardware, does not scale easily, and records privacy-sensitive behavior. So the signal mostly stays out of reach.
- ScanTextGAN generates human-like scanpaths over any text, so a model can use the signal without an eye-tracker [1]. It improved sentiment, sarcasm, and four GLUE tasks; random noise in its place did not reproduce the gains [1], [2].
- The lasting point is about synthetic human feedback in general: it helps to the degree it keeps the structure of the real signal, and only while you remember it is not the real thing.
Reading is not a straight line
When you read this sentence, your eyes do not glide along it. They jump ahead, settle on some words longer than others, and occasionally go back. Psycholinguists call that trace of fixations and jumps a scanpath, and it lines up with how hard the text was to process and which words carried the meaning.
That trace is useful to a machine. If a model knows which words a person would slow down on, it has a hint about what matters in the sentence. Researchers have used real eye-tracking this way to improve tasks like sentiment analysis, part-of-speech tagging, and named entity recognition [1].
The catch is collection. Real scanpaths come from putting people in front of an eye-tracker. The equipment is expensive, the setup does not scale to the data sizes modern NLP wants, and gaze behavior is personal information [1]. So a useful signal sits behind a practical and ethical bottleneck.
The figure below makes the idea concrete. The circles mark fixations, their size reflects fixation duration, and the arrows show how reading moves across the sentence, including skips and revisits.
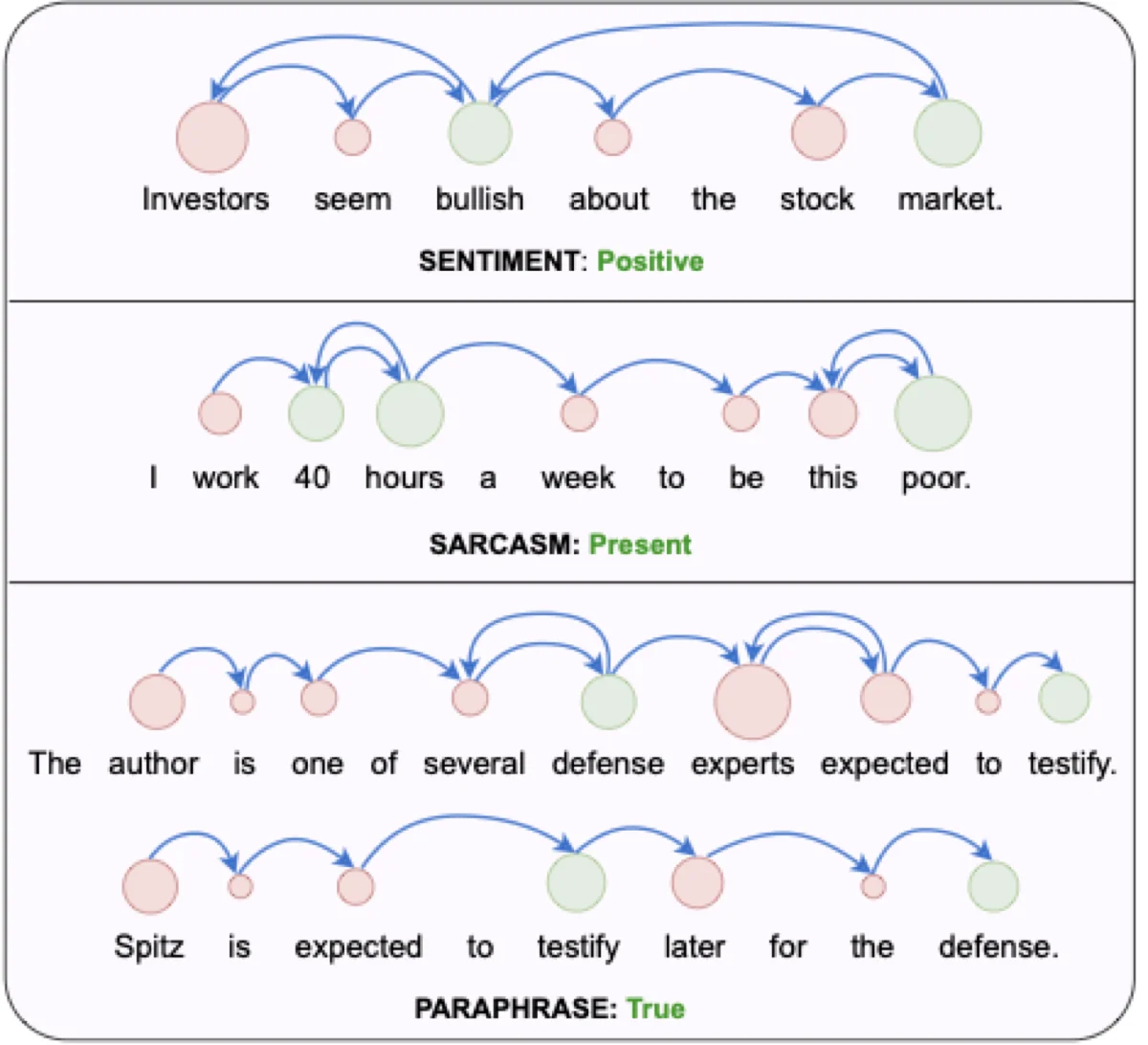
Model the signal instead of collecting it each time
ScanTextGAN starts from a narrower question. Rather than collect human reading traces for every new dataset, can a model learn to approximate them? Given a sentence, it outputs a scanpath: which words are fixated, in what order, for how long, including regressions to earlier words [1].
The model is a conditional GAN. A generator reads the sentence (BERT embeddings, plus noise so the output is not deterministic) and produces a scanpath. A discriminator tries to separate real human scanpaths from generated ones. Two additional losses keep the generator tied to the task: one matches predicted fixation points and durations to real eye-tracking traces, and one reconstructs the sentence representation so the scanpath remains linked to the input words [1]. Trained on the CELER corpus (365 readers, nearly 28,500 newswire sentences), it learns population-level patterns in how people move through text [3].
A synthetic signal that keeps useful structure
The obvious objection is fair: a generated scanpath is not a person reading a screen. It is an approximation learned from prior readers. So why should it help a real NLP task?
Because the approximation preserves part of the reading structure. The model is not impersonating one reader. It learns patterns such as skips, revisits, and longer fixations on words associated with processing difficulty or task relevance. On MultiMatch, the geometric scanpath metric used in this literature, the generated paths track real ones closely across in-domain and cross-domain datasets. On fixation duration, the reported scores are comparable to, and sometimes above, the inter-subject reference. On a blunter check, whether the model skips and attends the same words people do, it reaches 64.6 weighted F1 [1].
That does not make the generated trace equivalent to a human trace. It does suggest the output is structured enough to test downstream.
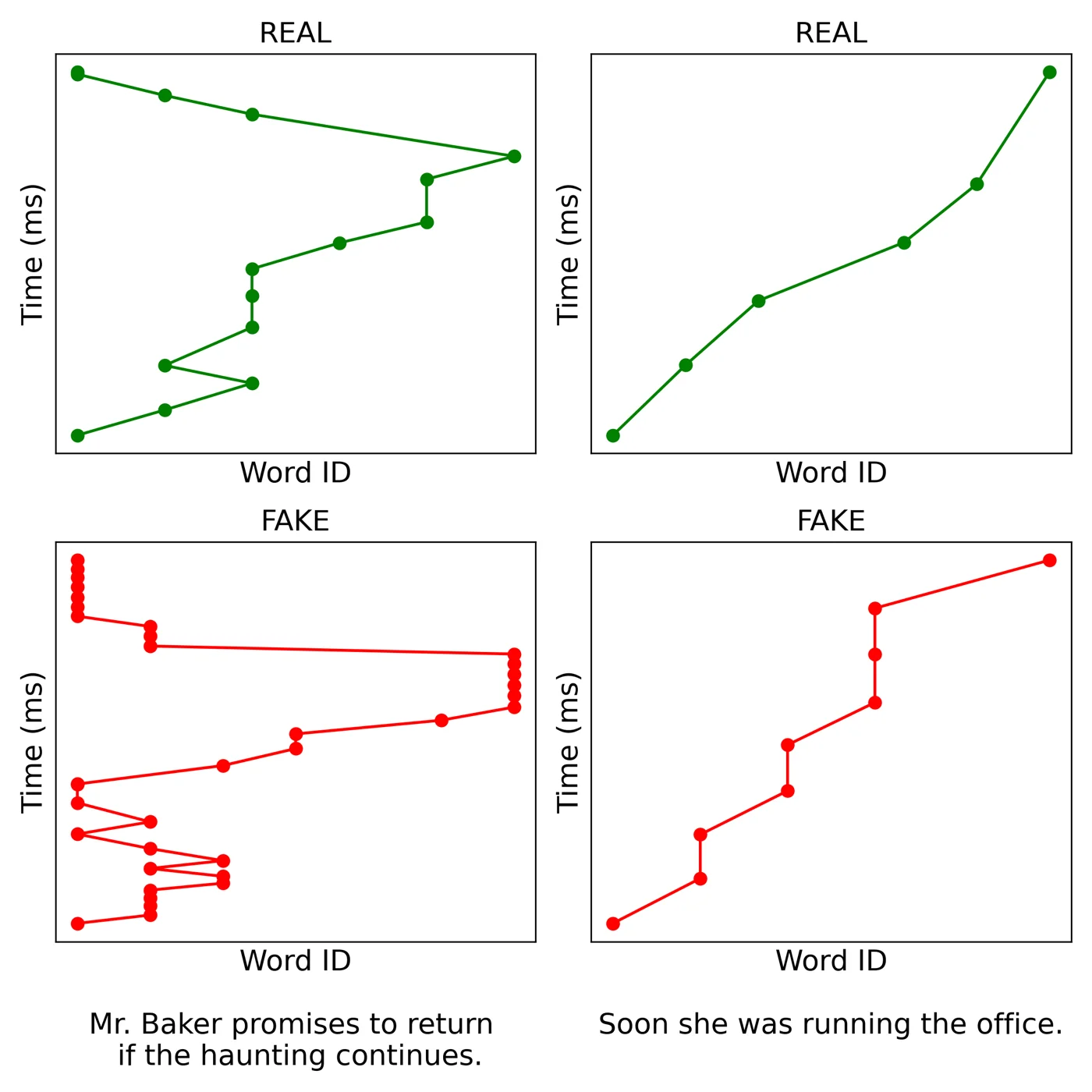
Does it actually help?
The downstream test was direct: add generated scanpaths to NLP models and compare them with the same models without scanpaths. We reported gains across sentiment analysis, sarcasm detection, and four GLUE tasks (SST, MRPC, RTE, QQP) [1], [2]. On the sentiment and sarcasm datasets, generated scanpaths delivered gains close to real scanpaths [1].
Two results are worth slowing down on, because they make the claim more credible.
The first is a control. We fed the model random noise in place of scanpaths, keeping the extra parameters. Performance fell back toward the baseline. The gains were not simply from making the model larger; they depended on the scanpath signal. That check is easy to skip, and without it the result would be much harder to interpret.
The second is more subtle. For sentiment and sarcasm, the best results came from training with real and generated scanpaths together, better than real alone [1]. We argued that the generated paths may bring additional cognitive information from CELER, the news-reading corpus used to train the generator, which is not fully present in the target eye-tracking dataset [1], [3]. That is a careful claim, and it matters: the synthetic signal may have added complementary structure rather than simply filling in a missing measurement.
There is a third piece that points forward. When the generator is trained with feedback from the downstream task, it produces intent-aware scanpaths, and the reading shifts toward the words that matter for that task. Reading a line for sentiment is not the same as reading it for entailment, and the model picks up the difference. On SST, sentiment accuracy went from 0.809 without scanpaths to 0.827 with intent-aware ones [1].
The part that outlives the paper
ScanTextGAN is from 2023, and scanpaths for NLP is a specific problem. The broader question has only become more important.
Many modern AI systems now rely on modeled or indirect human signals. RLHF trains on collected preferences. Synthetic data is used when real data is scarce. Language models are increasingly used to evaluate other language models. In each case, a human-centered signal is compressed, simulated, or approximated before it reaches the model.
ScanTextGAN is a controlled version of that problem, with useful checks built in. It carries two lessons worth keeping. A synthetic behavioral signal is useful to the degree it preserves the structure of the real signal, not merely its format. And it stays useful only while its limits remain visible. Treat the approximation as ground truth and you risk optimizing for the model of behavior rather than behavior itself.
The scientifically honest version of synthetic data holds both facts at once: it can work, and it is not the real thing.
Where this could go next
The most immediate direction is better data. ScanTextGAN learns from existing eye-tracking corpora, so larger and more diverse reading datasets would let future models handle longer text, different domains, and more reader variation [1]. That matters if scanpaths are going to move beyond sentence-level classification into settings where context builds over paragraphs.
The second direction is context. Real reading depends on what came before: the previous sentence, the task, the reader’s uncertainty, even a word that looked unimportant until later. Modeling intra- and inter-sentence scanpaths would make the synthetic signal closer to how people actually process language over time.
The third direction is language generation. If synthetic scanpaths can help classifiers, a natural next question is whether cognitive signals can shape what a model writes and what it expects a reader to notice, skip, or struggle with. That is also where explicit feedback (preferences, ratings) and implicit feedback (gaze, reading time, attention traces) may become more useful together than either is alone.
Takeaways
- Treat synthetic behavioral data as a structured proxy, not a replacement for people. The useful question is not whether the generated signal is “real” but whether it preserves the part of the human signal your model needs.
- Always run a matched noise control. If random input with the same model capacity gives the same gain, the model is benefiting from extra parameters, not from the behavioral signal.
- Do not frame real and synthetic data as a strict choice. In ScanTextGAN, combining real and generated scanpaths worked better than real scanpaths alone for sentiment and sarcasm, suggesting that synthetic signals can sometimes add complementary structure.
- Match the signal to the task. People do not read the same way for sentiment, entailment, or paraphrase; models that use human feedback should not treat attention as one fixed object either.
References
- Synthesizing Human Gaze Feedback for Improved NLP PerformanceProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp. 1895–1908. DOI: 10.18653/v1/2023.eacl-main.139. link
- GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language UnderstandingProceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 353–355. DOI: 10.18653/v1/W18-5446. link
- CELER: A 365-participant corpus of eye movements in L1 and L2 English readingOpen Mind. DOI: 10.1162/opmi_a_00054. link
Note: The opinions expressed on this blog are my own and do not necessarily reflect the views of my employer or any affiliated organization.