Publications
Publications by categories in reversed chronological order.
Note: For an up-to-date list of publications and patents, please refer to my Google Scholar profile.
2026
- WACV
 BrandFusion: Aligning Image Generation with Brand StylesParul Gupta, Varun Khurana, Yaman Kumar Singla, and 2 more authorsIn Winter Conference on Applications of Computer Vision, 2026
BrandFusion: Aligning Image Generation with Brand StylesParul Gupta, Varun Khurana, Yaman Kumar Singla, and 2 more authorsIn Winter Conference on Applications of Computer Vision, 2026While recent text-to-image models excel at generating realistic content, they struggle to capture the nuanced visual characteristics that define a brand’s distinctive style—such as lighting preferences, photography genres, color palettes, and compositional choices. This work introduces BrandFusion, a novel framework that automatically generates brand-aligned promotional images by decoupling brand style learning from image generation. Our approach consists of two components: a Brand-aware Vision-Language Model (BrandVLM) that predicts brand-relevant style characteristics and corresponding visual embeddings from marketer-provided contextual information, and a Brand-aware Diffusion Model (BrandDM) that generates images conditioned on these learned style representations. Unlike existing personalization methods that require separate fine-tuning for each brand, BrandFusion maintains scalability while preserving interpretability through textual style characteristics. Our method generalizes effectively to unseen brands by leveraging common industry sector-level visual patterns. Extensive evaluation demonstrates consistent improvements over existing approaches across multiple brand alignment metrics, with a 66.11% preference rate in human evaluation study. This work paves the way for AI-assisted on-brand content creation in marketing workflows.
@inproceedings{gupta2026brandfusion, title = {BrandFusion: Aligning Image Generation with Brand Styles}, author = {Gupta, Parul and Khurana, Varun and Singla, Yaman Kumar and Krishnamurthy, Balaji and Dhall, Abhinav}, booktitle = {Winter Conference on Applications of Computer Vision}, year = {2026}, }
2025
- ICLR
 Measuring And Improving Engagement of Text-to-Image Generation ModelsVarun Khurana*, Yaman Kumar Singla*, Jayakumar Subramanian, and 4 more authorsIn International Conference on Learning Representations, 2025
Measuring And Improving Engagement of Text-to-Image Generation ModelsVarun Khurana*, Yaman Kumar Singla*, Jayakumar Subramanian, and 4 more authorsIn International Conference on Learning Representations, 2025Recent advances in text-to-image generation have achieved impressive aesthetic quality, making these models usable for both personal and commercial purposes. However, in the fields of marketing and advertising, images are often created to be more engaging, as reflected in user behaviors such as increasing clicks, likes, and purchases, in addition to being aesthetically pleasing. To this end, we introduce the challenge of optimizing the image generation process for improved viewer engagement. In order to study image engagement and utility in real-world marketing scenarios, we collect EngagingImageNet, the first large-scale dataset of images, along with associated user engagement metrics. Further, we find that existing image evaluation metrics like aesthetics, CLIPScore, PickScore, ImageReward, etc. are unable to capture viewer engagement. To address the lack of reliable metrics for assessing image utility, we use the EngagingImageNet dataset to train EngageNet, an engagement-aware Vision Language Model (VLM) that predicts viewer engagement of images by leveraging contextual information about the tweet content, enterprise details, and posting time. We then explore methods to enhance the engagement of text-to-image models, making initial strides in this direction. These include conditioning image generation on improved prompts, supervised fine-tuning of stable diffusion on high-performing images, and reinforcement learning to align stable diffusion with EngageNet-based reward signals, all of which lead to the generation of images with higher viewer engagement. Finally, we propose the Engagement Arena, to benchmark text-to-image models based on their ability to generate engaging images, using EngageNet as the evaluator, thereby encouraging the research community to measure further advances in the engagement of text-to-image modeling. These contributions provide a new pathway for advancing utility-driven image generation, with significant implications for the commercial application of image generation. We have released our code and dataset on behavior-in-the-wild.github.io/image-engagement.
@inproceedings{khurana2025engagement, title = {Measuring And Improving Engagement of Text-to-Image Generation Models}, author = {Khurana, Varun and Singla, Yaman Kumar and Subramanian, Jayakumar and Chen, Changyou and Shah, Rajiv Ratn and Xu, Zhiqiang and Krishnamurthy, Balaji}, booktitle = {International Conference on Learning Representations}, year = {2025}, } - WACV
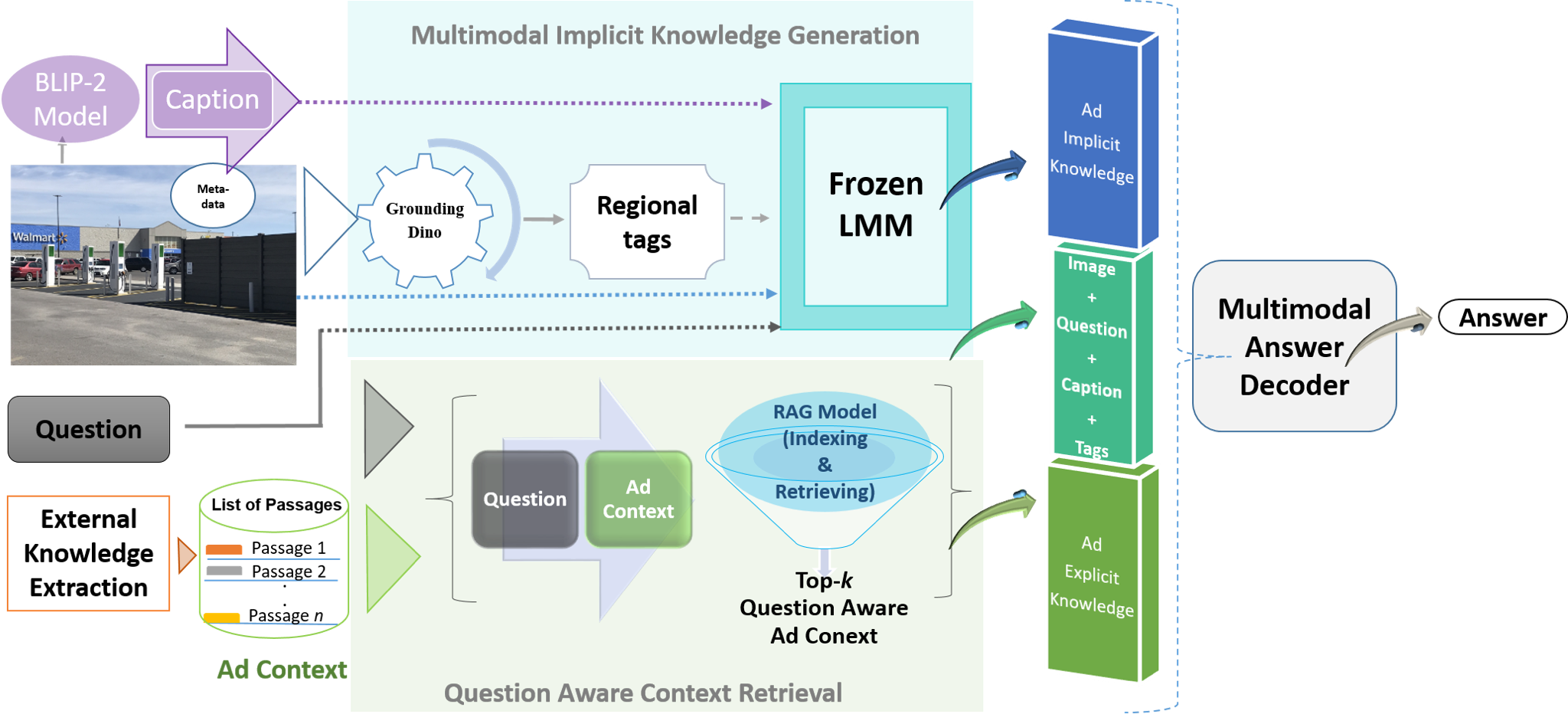 AdQuestA: Knowledge-Guided Visual Question Answer Framework for AdvertisementsNeha Choudhary, Poonam Goyal, Devashish Siwatch, and 4 more authorsIn Winter Conference on Applications of Computer Vision, 2025
AdQuestA: Knowledge-Guided Visual Question Answer Framework for AdvertisementsNeha Choudhary, Poonam Goyal, Devashish Siwatch, and 4 more authorsIn Winter Conference on Applications of Computer Vision, 2025In the rapidly evolving landscape of digital marketing, effective customer engagement through advertisements is crucial for brands. Thus, computational understanding of ads is pivotal for recommendation, authoring, and customer behaviour simulation. Despite advancements in knowledge-guided visual-question-answering (VQA) models, existing frameworks often lack domain-specific responses and suffer from a dearth of benchmark datasets for advertisements. To address this gap, we introduce ADVQA, the first dataset for ad-related VQA sourced from Facebook and X (twitter), which facilitates further research in ad comprehension. It comprises open-ended questions and detailed context obtained automatically from web articles. Moreover, we present AdQuestA, a novel multimodal framework for knowledge-guided open-ended question-answering tailored to advertisements. AdQuestA leverages a Retrieval Augmented Generation (RAG) to obtain question-aware ad context as explicit knowledge and image-grounded implicit knowledge, effectively exploiting inherent relationships for reasoning. Extensive experiments corroborate its efficacy, yielding state-of-the-art performance on the AD-VQA dataset, even surpassing 10X larger models such as GPT-4 on this task. Our framework not only enhances understanding of ad content but also advances the broader landscape of knowledge-guided VQA models.
@inproceedings{choudhary2025adquesta, title = {AdQuestA: Knowledge-Guided Visual Question Answer Framework for Advertisements}, author = {Choudhary, Neha and Goyal, Poonam and Siwatch, Devashish and Chandak, Atharva and Mahajan, Harsh and Khurana, Varun and Kumar, Yaman}, booktitle = {Winter Conference on Applications of Computer Vision}, year = {2025}, }
2023
- EACL
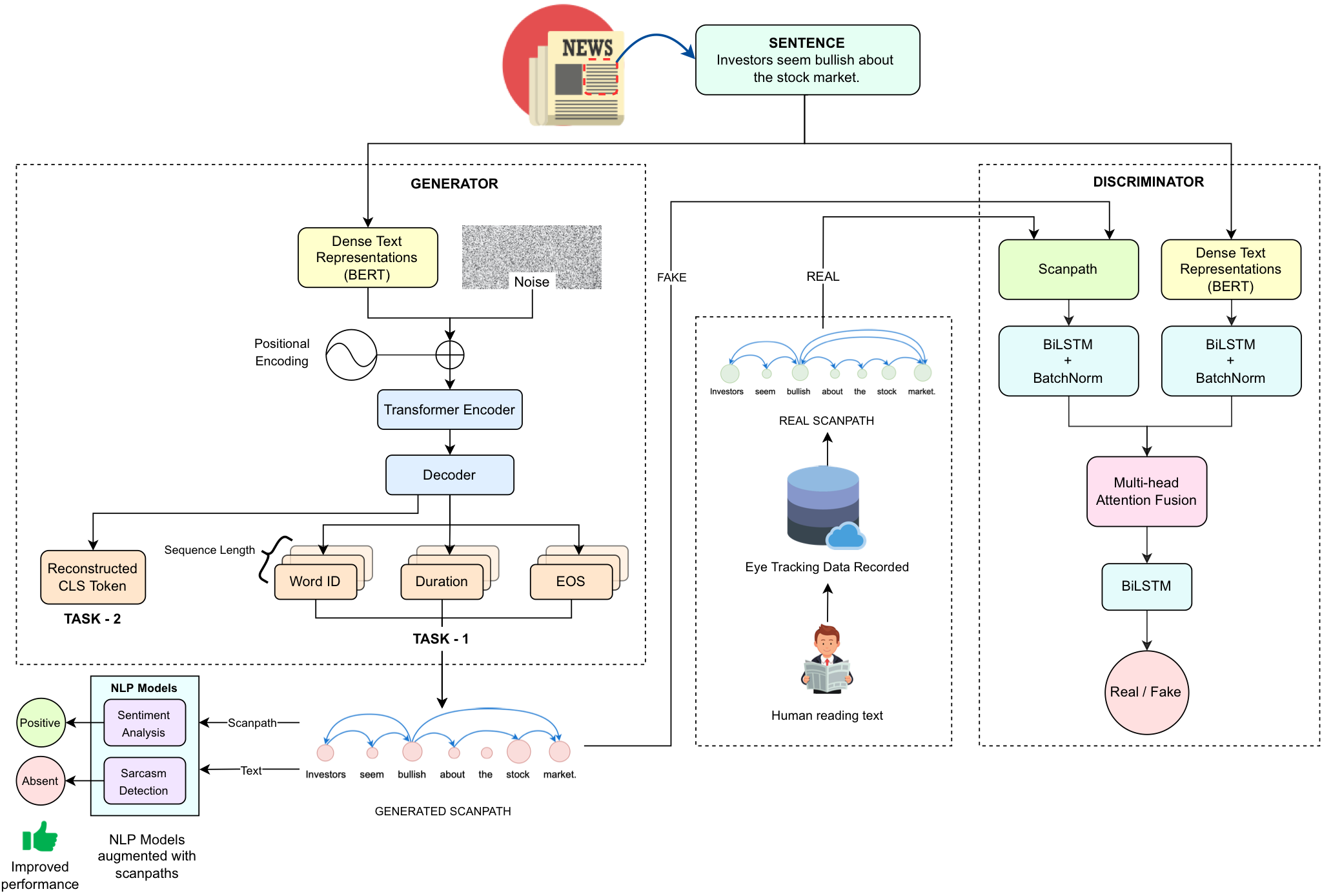 Synthesizing Human Gaze Feedback for Improved NLP PerformanceVarun Khurana*, Yaman Kumar*, Nora Hollenstein, and 2 more authorsIn European Chapter of the Association for Computational Linguistics, 2023
Synthesizing Human Gaze Feedback for Improved NLP PerformanceVarun Khurana*, Yaman Kumar*, Nora Hollenstein, and 2 more authorsIn European Chapter of the Association for Computational Linguistics, 2023Integrating human feedback in models can improve the performance of natural language processing (NLP) models. Feedback can be either explicit (e.g. ranking used in training language models) or implicit (e.g. using human cognitive signals in the form of eyetracking). Prior eye tracking and NLP research reveal that cognitive processes, such as human scanpaths, gleaned from human gaze patterns aid in the understanding and performance of NLP models. However, the collection of real eyetracking data for NLP tasks is challenging due to the requirement of expensive and precise equipment coupled with privacy invasion issues. To address this challenge, we propose ScanTextGAN, a novel model for generating human scanpaths over text. We show that ScanTextGAN-generated scanpaths can approximate meaningful cognitive signals in human gaze patterns. We include synthetically generated scanpaths in four popular NLP tasks spanning six different datasets as proof of concept and show that the models augmented with generated scanpaths improve the performance of all downstream NLP tasks.
@inproceedings{khurana2023synthesizing, title = {Synthesizing Human Gaze Feedback for Improved NLP Performance}, author = {Khurana, Varun and Kumar, Yaman and Hollenstein, Nora and Kumar, Rajesh and Krishnamurthy, Balaji}, booktitle = {European Chapter of the Association for Computational Linguistics}, year = {2023}, }
2022
- NAACL-HLT
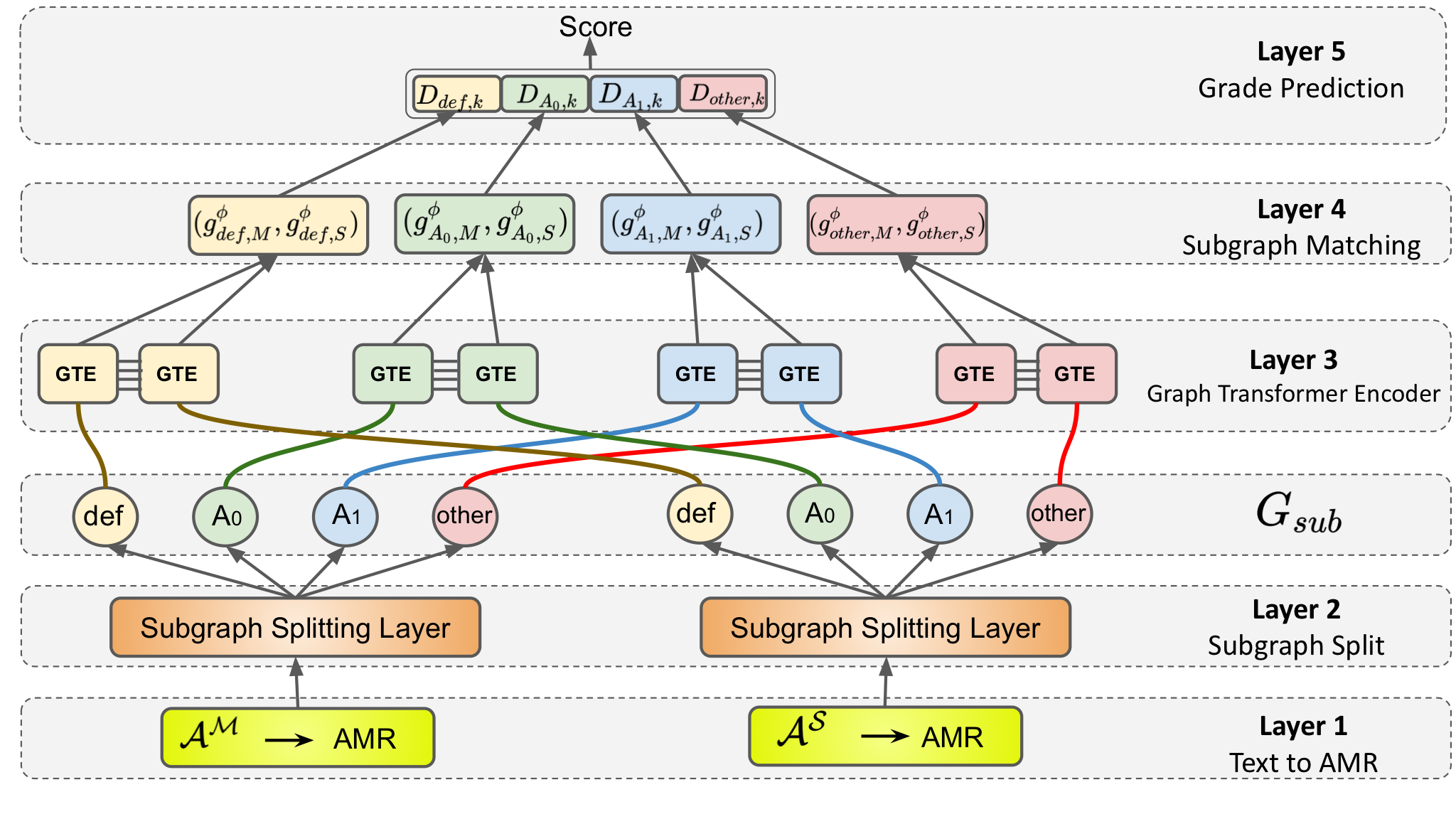 Multi-Relational Graph Transformer for Automatic Short Answer GradingRajat Agarwal, Varun Khurana*, Karish Grover*, and 2 more authorsIn North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2022ORAL Presentation
Multi-Relational Graph Transformer for Automatic Short Answer GradingRajat Agarwal, Varun Khurana*, Karish Grover*, and 2 more authorsIn North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2022ORAL PresentationThe recent transition to the online educational domain has increased the need for Automatic Short Answer Grading (ASAG). ASAG automatically evaluates a student’s response against a (given) correct response and thus has been a prevalent semantic matching task. Most existing methods utilize sequential context to compare two sentences and ignore the structural context of the sentence; therefore, these methods may not result in the desired performance. In this paper, we overcome this problem by proposing a Multi-Relational Graph Transformer, MitiGaTe, to prepare token representations considering the structural context. Abstract Meaning Representation (AMR) graph is created by parsing the text response and then segregated into multiple subgraphs, each corresponding to a particular relationship in AMR. A Graph Transformer is used to prepare relation-specific token embeddings within each subgraph, then aggregated to obtain a subgraph representation. Finally, we compare the correct answer and the student response subgraph representations to yield a final score. Experimental results on Mohler’s dataset show that our system outperforms the existing state-of-the-art methods. We have released our implementation https://github.com/kvarun07/asag-gt, as we believe that our model can be useful for many future applications.
@inproceedings{agarwal2022multirelational, title = {Multi-Relational Graph Transformer for Automatic Short Answer Grading}, author = {Agarwal, Rajat and Khurana, Varun and Grover, Karish and Mohania, Mukesh and Goyal, Vikram}, booktitle = {North American Chapter of the Association for Computational Linguistics: Human Language Technologies}, year = {2022}, note = {ORAL Presentation}, }
Patents
2026
- Patent FiledCode generation from a digital imageIshika Goel , Varun Khurana , Rishabh Jain , Rahul Gupta , Mayank Gupta , and Anubhav TripathiU.S. Patent Application 18/779,576 , 2026
@misc{goel2026codegen, title = {Code generation from a digital image}, author = {Goel, Ishika and Khurana, Varun and Jain, Rishabh and Gupta, Rahul and Gupta, Mayank and Tripathi, Anubhav}, year = {2026}, note = {U.S. Patent Application 18/779,576}, type = {Patent Application}, status = {Filed}, }
2023
- Patent FiledSystems and methods for generating scanpathsYaman Kumar and Varun KhuranaU.S. Patent Application 18/109,990 , 2023
@misc{kumar2023scanpaths, title = {Systems and methods for generating scanpaths}, author = {Kumar, Yaman and Khurana, Varun}, year = {2023}, note = {U.S. Patent Application 18/109,990}, type = {Patent Application}, status = {Filed}, }
2022
- Patent FiledAttention aware multi-modal model for content understandingYaman Kumar , Vaibhav Ahlawat , Ruiyi Zhang , Milan Aggarwal , Ganesh Karbhari Palwe , Balaji Krishnamurthy , and Varun KhuranaU.S. Patent Application 17/944,502 , 2022
@misc{kumar2022multimodal, title = {Attention aware multi-modal model for content understanding}, author = {Kumar, Yaman and Ahlawat, Vaibhav and Zhang, Ruiyi and Aggarwal, Milan and Palwe, Ganesh Karbhari and Krishnamurthy, Balaji and Khurana, Varun}, year = {2022}, note = {U.S. Patent Application 17/944,502}, type = {Patent Application}, status = {Filed}, }